#(转)与一伙爬虫团队的斗智斗勇
近期发生了公司系统遭受大规模爬虫攻击的事件。在国庆节后出现了注册但未下单的用户进行多次请求,初步定位为爬虫用户并采取了集团IP封锁的方法,但是爬虫团队逐渐增强,并且攻击手法更加隐蔽。由于防护策略不断升级,导致爬虫团队进化速度快于技术人员的掌控能力,最终导致技术人员全面告败的局面。
爬虫逐渐 摸索出服务器特点,从 多IP 多用户ID 请求频率(突发到半小时 到跟正常用户一样,),相当于模拟了500用户正常看内容....
#提高DAU了...顺带压测服务器...
#反爬系统设计
我们针对反爬系统进行了简单的设计,其实一个反爬系统最重要的主要有三部分组成:爬虫识别、爬虫处理和误伤洗白。
#基于访问量
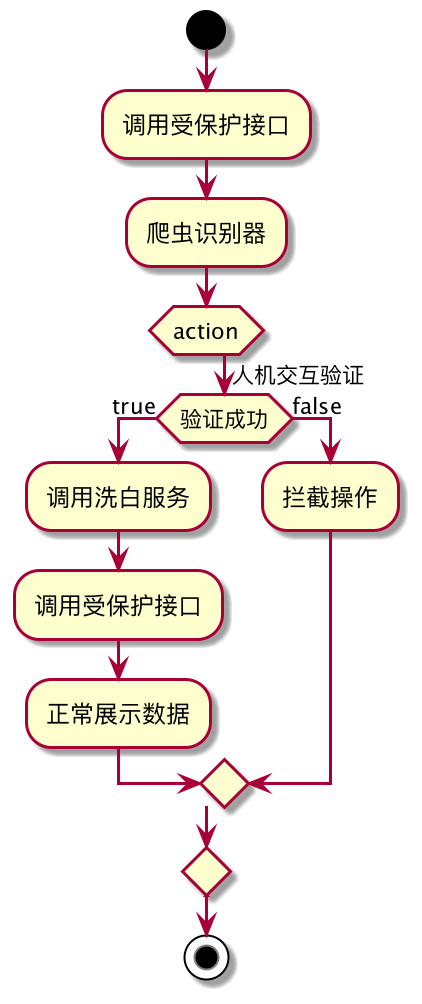
#基于人机交互的识别方式
#加解密识别方式
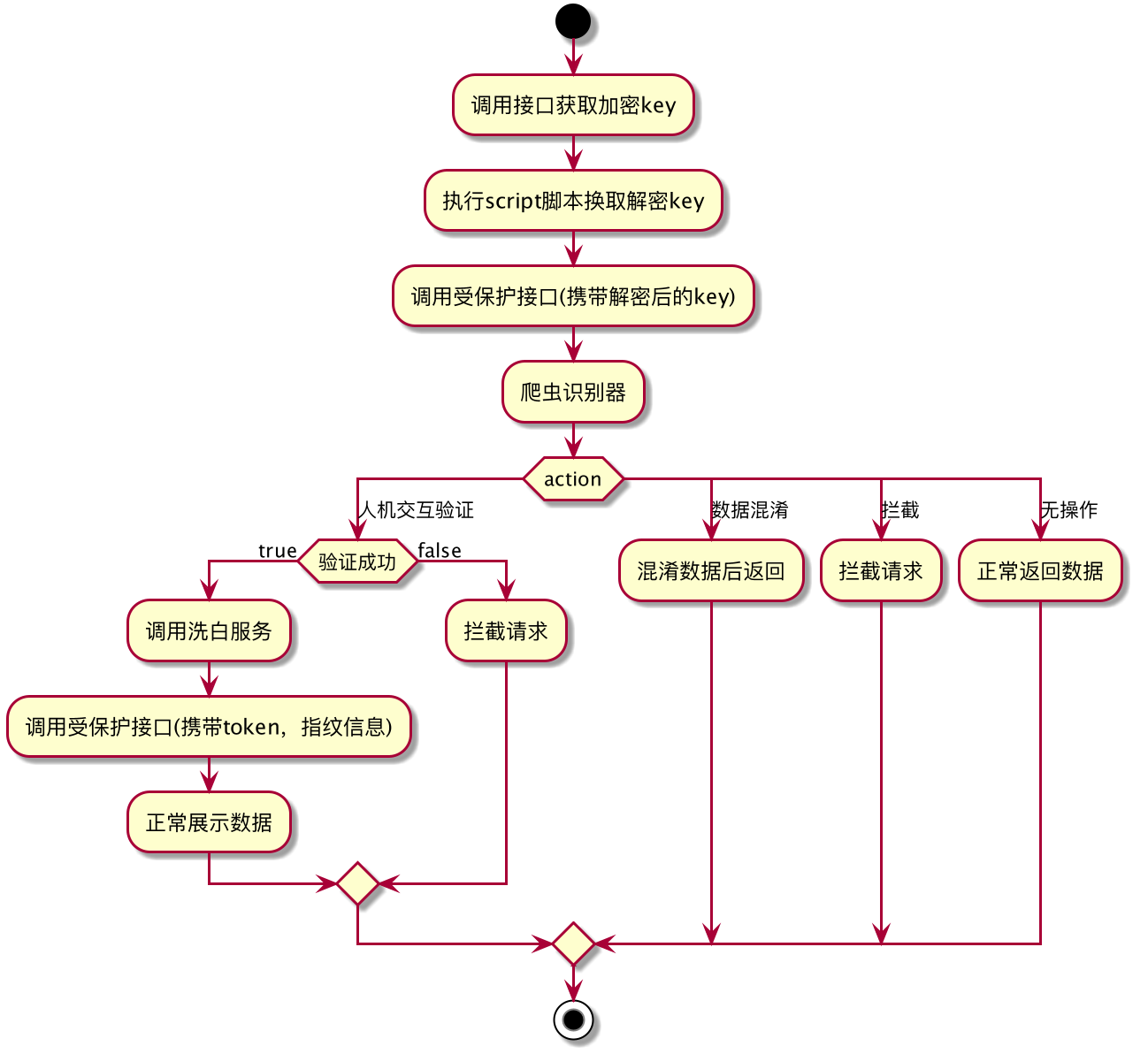
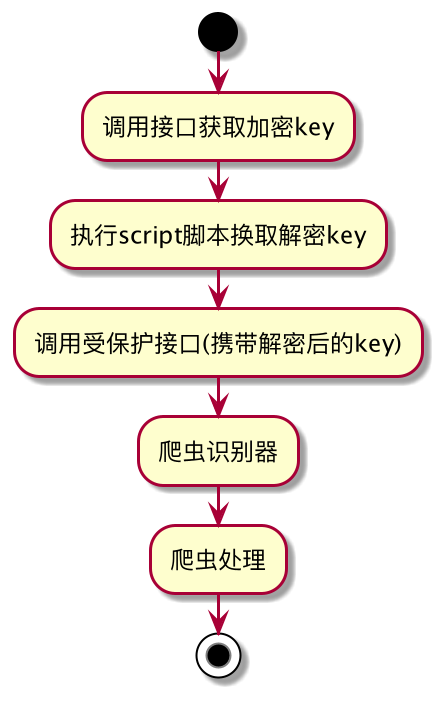
加解密也是常用的爬虫识别手段之一,原理也比较简单,即服务端下发加密 key,由客户端执行解密,然后受保护的接口需要传入解密后的 key,服务端来验证是否合法。
#爬虫处理
- 直接拦截
- 数据混淆 这种方式要复杂一些,就是在识别到爬虫后,并不会直接拦截,而是将数据混淆,返回给对方一些迷惑性的数据,让其不知道我们已经发现了他们,但实际上爬取到的都是一些无用的数据。但这种方式也有很大的风险,一旦误伤很容易引起投诉。 原先开发游戏那会,我们经常用
- 人机交互
- 洗白!!!。 没有万能的,一定做好 洗白方式