#大模型-概念-扫盲贴(持续更新)
Agent 是什么,直译过来就是代理,但在国内人工智能领域通常被译为智能体。大模型大大降低了智能体实现的门槛
智能体 = 推理 + 生成 + 工具调用
Prompt 是给予提供语言模型(LLM)的输入或查询,作为模型生成后续文本的起点或上下文,它指示模型应生成何种类型的响应或输出。
LLM(Large Language Model)即大型语言模型,是近年来人工智能领域的重要技术突破。基于深度学习技术的自然语言处理工具,能理解和生成文本。
Transformer架构,利用自注意力机制捕捉上下文关联
GPT(Generative Pretrained Transformer)和 BERT(Bidirectional Encoder Representations from Transformers)这两个词中的 T 就是 Transformer 架构。Transformer 架构是一种基于自注意力机制的神经网络结构,它完全颠覆了之前以循环神经网络(RNN)为主导的序列建模范式。Transformer 架构的出现,实现了并行计算和高效的上下文捕获,极大地提高了自然语言处理的性能。可以说,先有 Transformer,后有 GPT 以及 BERT。 常见模型中的 7B,14B,32B...等参数 B 是 Billion 的缩写,指的是模型训练的参数数量。
OpenManus是Manus的开源版本
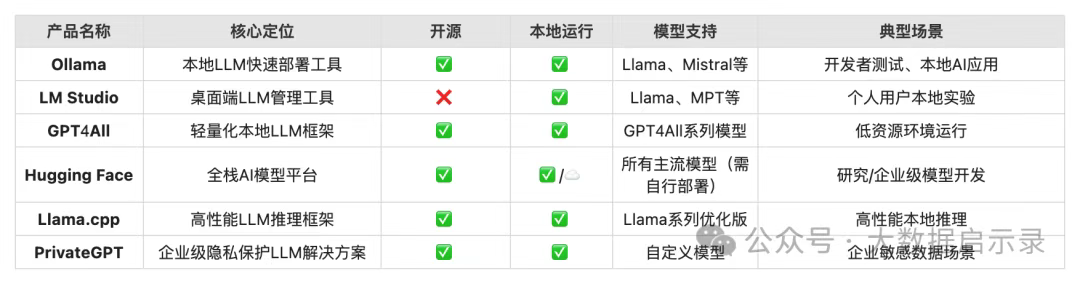
Ollama 是一个开源的框架,旨在简化大型语言模型的部署和管理。它提供了一个轻量级的 HTTP 服务,允许用户通过 API 接口与模型进行交互。 Ollama 默认开放 11434 端口,且无任何鉴权机制。
vLLM 是一个专为大语言模型(LLMs)设计的高效推理库,旨在优化推理速度和内存使用。
Xinference 是针对生成式 AI 场景度身定制的能力全面的推理服务平台。
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。
AIGC,即人工智能生成内容(Artificial Intelligence Generated Content),是一种利用人工智能算法和技术自动生成各种形式的内容的技术。 AIGC产品: 文本生成:OpenAI GPT系列、Google BERT系列、Anthropic Claude、Alibaba Qwen、Microsoft Copilot。图像生成:DALL-E、Midjourney、Stable Diffusion、DeepArt、RunwayML。音频生成:Jukebox、WaveNet、MusicGen、Amper Music、Descript。视频生成:DeepMind VideoGen、RunwayML Video、Daz 3D、Synthesia、Adobe After Effects with AI Plugins,Sora,runway。其他应用:Adobe Firefly、Notion AI、GitHub Copilot、Replit AI、Grammarly。
RAG(Retrieval Augmented Generation)检索增强生成,即大模型LLM在回答问题或生成文本时,会先从大量的文档中检索出相关信息,然后基于这些检索出的信息进行回答或生成文本,从而可以提高回答的质量,而不是任由LLM来发挥。
MCP MCP(Model Context Protocol,模型上下文协议) 是由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
模型蒸馏(Model Distillation):是一种模型压缩和知识迁移的技术,旨在将一个大型、复杂且性能优异的教师模型(Teacher Model)中的知识传递给一个较小、计算效率更高的学生模型(Student Model),将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力,复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
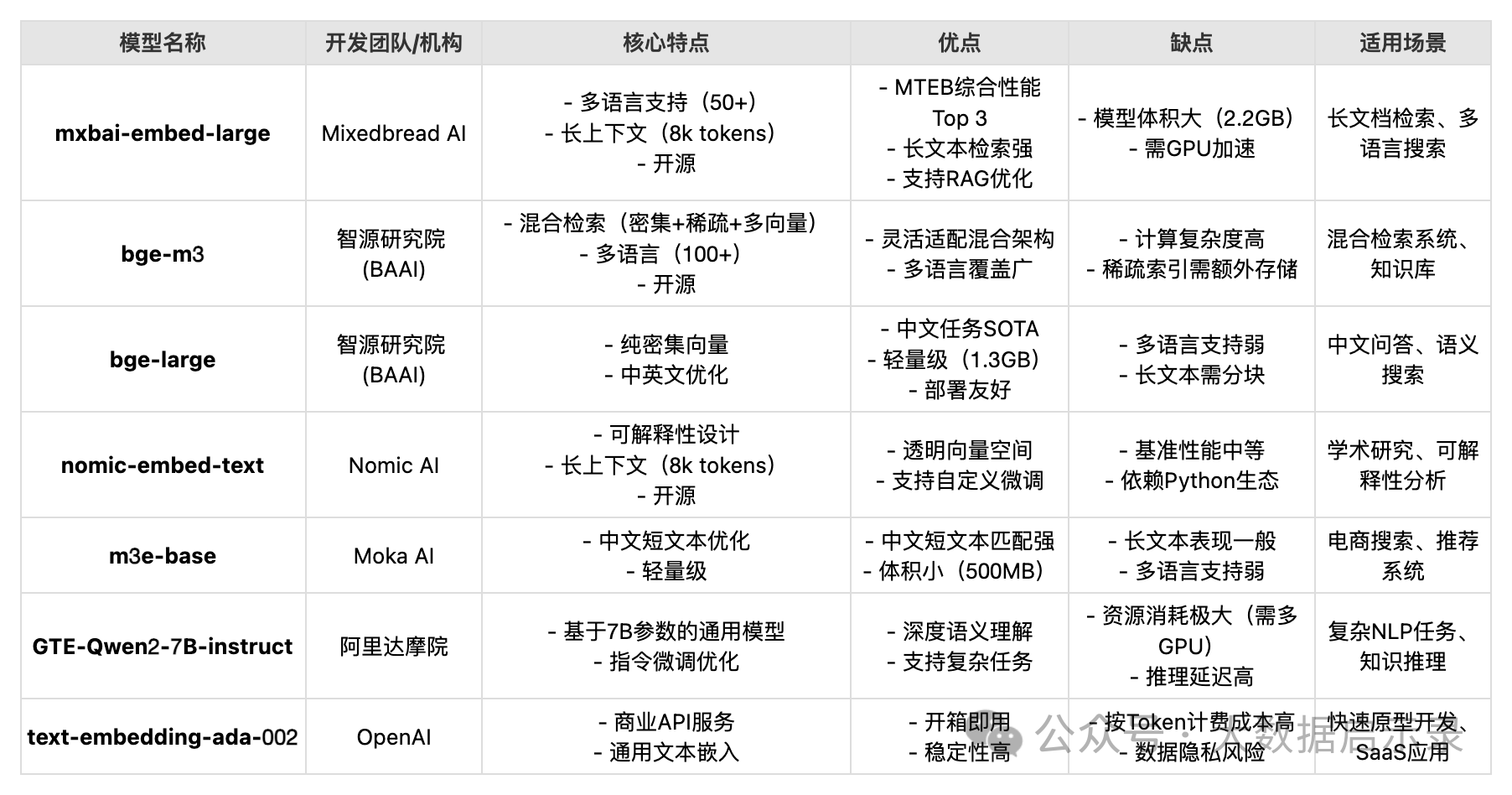
- Embedding模型
Embedding: 这是一个通用术语,指的是将数据(可以是词、句子、图像等)转换成数值向量形式的过程。这些向量捕捉了数据的某些特征或属性,使得机器学习算法能够处理。可以应用于多种类型的数据,不仅限于文本,还可以是图像、声音等,而词嵌入特指文本中的单词或短语的嵌入。 Embedding 通常指将高维度的数据映射到低维度的空间中 。
#强烈推荐:
https://mp.weixin.qq.com/s/nr8QEjMJo0SbyCduDehoMw https://mp.weixin.qq.com/s/rkEiac1zbSjHL1U5AIJzZA