HBase LSM 树存储引擎概要
- 前提
=====
讲 LSM 树之前,需要提下三种基本的存储引擎,这样才能清楚 LSM 树的由来:
- 哈希存储引擎。
- B 树存储引擎。
- LSM 树(Log-Structured Merge Tree)存储引擎。
- 哈希存储引擎
=========
哈希存储引擎哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为 key-value 存储系统。对于 key-value 的插入以及查询,哈希表的复杂度都是 O(1),明显比树的操作 O(n) 快,如果不需要有序的遍历数据,哈希表就非常适合。代表性的数据库有:Redis,Memcache,以及存储系统 Bitcask。
举例 Bitcask 的哈希表数据结构为:
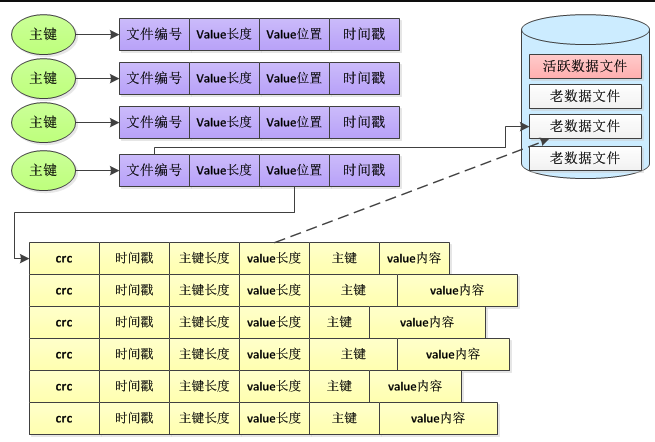
Bitcask 数据文件中的数据是一条一条写入操作,记录包含 key、value、主键长度、value 长度、时间戳以及 crc 校验值。
数据库所在服务器在内存中采用基于哈希表的索引数据结构,哈希表的作用是通过主键快速地定位到 value 的位置。哈希表结构中的每一项包含了三个用于定位数据的信息,分别是文件编号(file id),value 在文件中的位置(value_pos),value 长度(value_sz),通过读取 file_id 对应文件的 value_pos 开始的 value_sz 个字节,这就得到了最终的 value 值。写入时首先将 key-value 记录追加到活跃数据文件的末尾,接着更新内存哈希表,因此,每个写操作总共需要进行一次顺序的磁盘写入和一次内存操作。
Bitcask 在内存中存储了主键和 value 的索引信息,磁盘文件中存储了主键和 value 的实际内容。
- B 树存储引擎
==========
相比哈希存储引擎,B 树存储引擎不仅支持随机读取,还支持范围扫描。关系型数据库中通过索引访问数据,在 Mysql InnoDB 中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成 B + 树(B 树的一种)数据结构。
B + 树的数据结构:
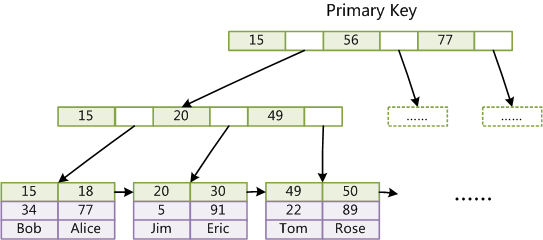
如图所示,MySQL InnoDB 按照页面(Page)来组织数据,每个页面对应 B + 树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B + 树的根节点是常驻内存的,因此,B + 树一次检索最多需要 h-1 次磁盘 IO,复杂度为 O(h)=O(logdN)(N 为元素个数,d 为每个节点的出度,h 为 B + 树高度)。修改操作首先需要记录提交日志,接着修改内存中的 B + 树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
4. LSM 树存储引擎
4.1 LSM 主题思想
LSM-Tree 主题思想为划分不同等级的数。可以想象一份索引由两棵树组成:一个存在于内存(可以使用其他树结构),一个存在于磁盘(如下图)。
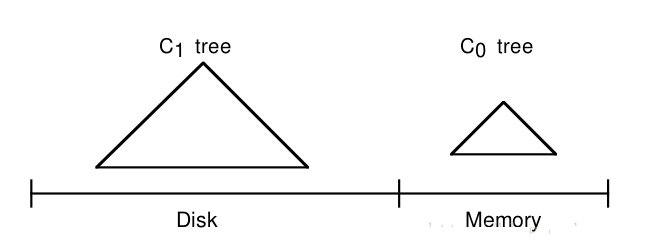
LSM 树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的来说,基于 LSM 树实现的 HBase 的写性能比 Mysql 高了一个数量级,读性能低了一个数量级。
数据首先会插入到内存中的树,为了防止数据丢失,写内存的同时需要暂时持久化到磁盘,即输入数据时数据会以完全有序的形式先存储在日志文件中(对应 HBase 的 MemStore 和 HLog)。当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当内存中树的数据达到阀值时,会进行合并操作。合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并,当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘。同时更新父亲节点对叶子节点的指针(如下图)。
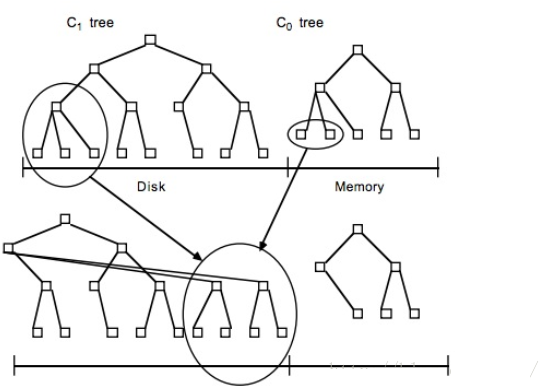
查找通过合并的方式完成,首先搜索内存存储结构,接下来是磁盘存储结构。
LSM 树所有节点都是满的并按页存储,经过多次的 flush 会创建很多数据存储文件,后台线程会将小文件聚合成大文件,因此磁盘的寻道操作就会被限制在一定数目的数据存储文件中,以优化读性能。磁盘上的树结构也可以分割成多个存储文件,因为所有的存储数据都是按照 Key 有序排列的,因此在现有节点中插入新的关键字不需要重新排序。
LSM-Tree 属于传输型,在磁盘传输速率上进行文件的排序和合并以及日志操作,可以更好的拓展到更大的数据规模上,因为它会使用日志文件和一个内存存储结构把随机写操作转化为顺序写,读写独立,不会产生两种操作的竞争。
4.2 LSM 树在 HBase 中的应用
LSM 树可以看成 n 层合并树。在 HBase 中,它把随机写转换成对 MemStore 和 HFile 的连续写。下图展示了 LSM 树数据写的过程。
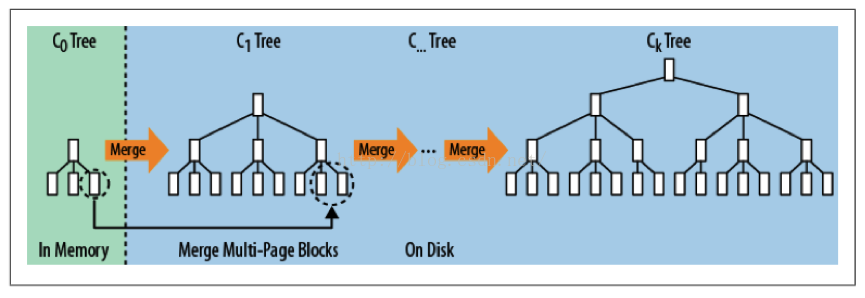
**数据写(插入,更新):**数据首先顺序写如 HLog(WAL),然后写到 MemStore,在 MemStore 中,数据是一个 2 层 B + 树(上图中的 C0 树)。MemStore 满了之后,数据会被刷到 StoreFile(HFile),在 StoreFile 中,数据是 3 层 B + 树(图 2 中的 C1 树),并针对顺序磁盘操作进行优化。
**数据读:**首先搜索 MemStore,如果不在 MemStore 中,则到 StoreFile 中寻找。
**数据删除:**不会去删除磁盘上的数据,而是为数据添加一个删除标记。在随后的 major compaction 中,被删除的数据和删除标记才会真的被删除。
LSM 数据更新只在内存中操作,没有磁盘访问,因此比 B + 树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM 树能减少磁盘访问,提高性能。
总结
原文地址 www.cnblogs.com