mysql 字符串索引 优化
https://www.cnblogs.com/michael9/p/13219915.html
字符串建立索引的优化#
1. 建立前缀索引#
假设建立一个支持邮箱登录的用户表,对于邮件字段来说,可以有以下几种建立索引的方式:
直接对整个字符串建立索引
alter table SUser add index index1(email);
对整个字符串的前一部分建立索引 - 前缀索引
alter table SUser add index index2(email(6));
方式 2 相较于 方式 1 来说,利用前缀索引,占用的空间更小。但有可能造成性能的损失,读取数据的次数变多。
假设在 user 表中存在[email protected], [email protected] , [email protected], 三条记录。
有这样一条语句 select id,name,email from SUser where email='[email protected]';
使用 index1 索引时,流程如下:
在 index1 中,找到名字是 [email protected] 的记录,获取 ID.
在主键索引上对应 ID的行,判断 email 是否正确,将记录加入结果集。
接着取 index1 索引的下一条记录,发现不满足 email 格式,结束循环。
使用 index2 索引:
在 index2 中,找到名字是 zhangs 的记录,获取 ID.
在主键索引上对应 ID的行,这时拿到的是 [email protected] 的行, 发现不符合,丢弃。
接着在 index2 循环,拿到下一条记录 ID。
在主键索引上对应 ID的行,这时拿到的是 [email protected] 的行, 发现不符合,丢弃。
接着在 index2 循环,拿到下一条记录 ID。
在主键索引上对应 ID的行,这时拿到的是 [email protected] 的行, 发现符合,纳入结果集。
接着在 index2 循环,发现记录格式不符合,结束循环。
看这个过程,很容易发现,前缀索引会增加查询语句读取数据的次数。
但如果将前缀索引的 email(6) 改成 email(7),就会减少查询的次数,对应在主键索引上只搜索一次。这就说明,如果能合适的设置前缀索引的长度,就能在空间和效率上取得平衡。
如何找到合适的前缀索引长度
在建立索引时,应该去关注区分度,区分度越高,则说明重复的键值越少。
可以通过执行查询来统计列上有多少不同的值。
mysql> select
count(distinct email)as L,
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser;
接着确定业务上可以接受的顺势区分度,比如 5%, 用 L 的数量 * 区分度比例(1-5%=95%),然后看在 L4 到 L7 中哪个满足。
前缀索引的影响
在之前覆盖索引的文章中,如果查询的列的信息被包含在二级索引上,那么就可以避免回表的过程,进而减少查询次数,提供效率。但如果在建立索引时,使用了前缀索引,那么无论满不满足覆盖索引的规则,都会回表。因为系统不能确定前缀索引是否截取了完成信息,进而必须做一次判断。
也就是说,前缀索引除了会增加查询语句的次数,还会禁止使用覆盖索引。
2. 倒序存储#
对于邮箱这类的字符串来说,由于前几位有较大的区分度,所以用前缀索引还不错。但如果是区分度不好的情况,比如身份证,前 6 位都是地址码,很多人都会一样。这时如果想要使用前缀索引,就需要至少 12 位以上,对应查询效率和空间都不是很合适。
一个比较好的办法是将字符串倒序存储,将区分度高的字符开头。
例如:
mysql> select field_list from t
where id_card = reverse('input_id_card_string');
3. 使用 hash 字段#
在网络传输时,CRC - 循环冗余校验被用于检验文件。对应在 MySQL 里也有这个函数,crc32().
该函数的返回范围是 0-4294967296 也就是 4 字节,相对于其他字符串来说,属于较短的长度。
在创建表时,可再创建一个整数字段,来保存这类字符串,如身份证的校验码(crc32()的返回值), 并为该字段创建索引。
如:
mysql> alter table t add id_card_crc int unsigned,
add index(id_card_crc);
在插入记录时,将 crc32() 的结果插入到记录中。
但由于 crc32() 只有 32 位的特性,容易发生 hash 碰撞,就是说可能两个字符串经过计算后得到相同的验证码。这时就存在冲突,所以还需要判断下查询的值是否一致。
如:
mysql> select field_list from t where
id_card_crc=crc32('input_id_card_string') and
id_card='input_id_card_string'
总结#
我们知道,MySQL 中使用的是 B+ 树来存储索引的,这自然就是有序的,所以前缀查询就支持范围查询。
而 Hash 字段和倒序查询两种方式就不行了,倒序查询是按照倒序字符串存储的,而 hash 字段和字符串本身也没有关系,这就意味着这两种方式是不支持范围查询的。
在占用空间上来说,倒序存储占用的是和普通索引的一样的空间。而 hash 字段,需要增加一个字段来存在 hash 校验码。
在 CPU 消耗,倒序时,每次读和写都需要调用 reverse 函数。hash 方式需要额外调用 crc32() 函数。两个函数实现来看,reverse 函数 CPU 消耗会少些。
在查询效率上,hash 字段查询性能更好稳定些。虽然可能存在冲突的情况,但概率很小。而倒序存储还是用前缀索引的方式,会额外增加扫描行数。
总结一下,一般提高查询字符串的效率有如下方式:
直接创建完成索引,但占用空间较大。
创建前缀索引,节省空间,但会增加扫描次数,不能利用覆盖索引。
倒序存储,再创建前缀索引,节省空间,增加扫描次数,不能利用覆盖索引。
hash 字段,性能稳定,但占用额外的空间,不支持范围查询。
字符逆序排列
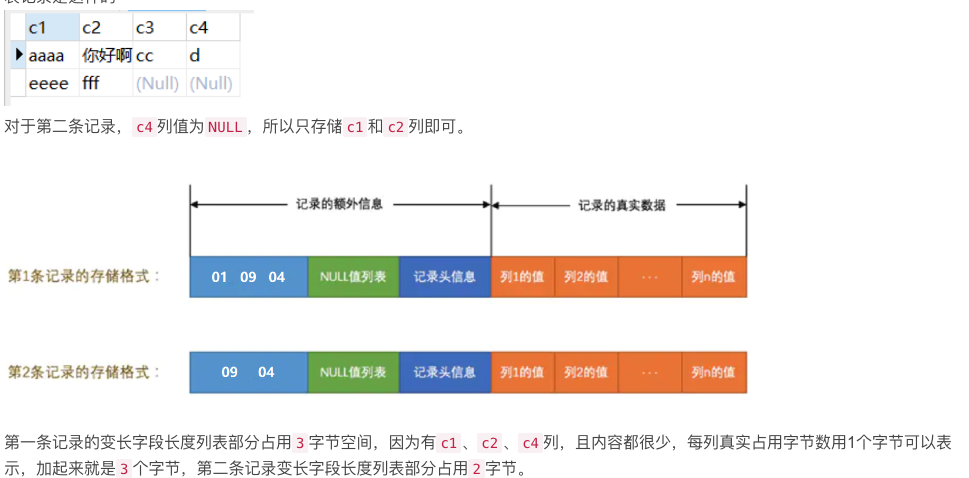
我们平时是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为 行格式 或者 记录格式 。 InnoDB 到现在为止设计了4种不同类型的 行格式 ,分别是 Compact 、 Redundant 、Dynamic 和 Compressed 行格式。
mysql5.0之后的默认行格式为Compact , 5.7之后的默认行格式为dynamic
https://blog.csdn.net/qq_34115899/article/details/117524328
InnoDB有它的一套规则,我们引入W、M和L这几个符号:
假设某个字符集中最多需要W字节来表示一个字符
utf8mb4字符集中的W就是4
utf8字符集中W就是3
gbk字符集中的W就是2
ascii字符集中的W就是1。
对于变长类型VARCHAR(M)来说,这种类型表示能存储最多M个字符(注意是字符不是字节)
所以这个类型能表示的字符串最多占用的字节数就是M × W。
假设它实际存储的字符串占用的字节数是L。
https://blog.csdn.net/qq_42435377/article/details/124951046
压缩传输
使用压缩协议连接
mysql压缩协议适合的场景是mysql的服务器端和客户端之间传输的数据量很大,或者可用带宽不高的情况,典型的场景有如下两个:
a、查询大量的数据,带宽不够(比如导出数据的时候)
##普通连接
mysql -hlocalhost -P666 -uroot -p123456 --compress
## 导出数据时
mysqldump -hlocalhost -P666 -uroot -p123456 -default-character-set=utf8 --compress --single-transaction test test > test.sql
b、复制的时候binlog量太大导致主从同步延迟。可以看到,开启slave_compressed_protocol=ON 后,带宽会得到了很大的压缩(节省了2/3的带宽),在跨机房同步的时候,可以避免专线的过高占用。
COLLATE
field1 text COLLATE utf8_unicode_ci NOT NULL COMMENT '字段1',
COLLATE utf8_unicode_ci,其实是用来排序的规则。对于mysql中那些字符类型的列,如VARCHAR,CHAR,TEXT类型的列,都需要有一个COLLATE类型来告知mysql如何对该列进行排序和比较。简而言之,COLLATE会影响到ORDER BY语句的顺序,会影响到WHERE条件中大于小于号筛选出来的结果,会影响DISTINCT、GROUP BY、HAVING语句的查询结果。另外,mysql建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和COLLATE有关。
COLLATE都带有_ci字样,这是Case Insensitive的缩写,即大小写无关,也就是说"A"和"a"在排序和比较的时候是一视同仁的。
对于那些_cs后缀的COLLATE,则是Case Sensitive,即大小写敏感的。
结论:推荐使用utf8mb4_unicode_ci,对于已经用了utf8mb4_general_ci的系统,也没有必要花时间改造。
从mysql8.0开始,默认的CHARSET已经改为了utf8mb4,默认的COLLATE改为了utf8mb4_0900_ai_ci。
https://www.cnblogs.com/qcloud1001/p/10033364.html
从mysql 8.0开始,mysql默认的CHARSET已经不再是Latin1了,改为了utf8mb4(参考链接),并且默认的COLLATE也改为了utf8mb4_0900_ai_ci。utf8mb4_0900_ai_ci大体上就是unicode的进一步细分,0900指代unicode比较算法的编号( Unicode Collation Algorithm version),ai表示accent insensitive(发音无关),例如e, è, é, ê 和 ë是一视同仁的。
CREATE TABLE (
field1 VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
……
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
优先级 列 > 表> 库