惊群效应
原文地址 blog.csdn.net
什么是惊群效应
这个话题来自一个面试,当问到 Socket 编程中的 accept() 是否有惊群问题,引深又问到 epoll 多路复用中 epoll_wait() 是否有惊群问题。因为没有准备背过八股文,突然问到这个问题,还是稍微有点措手不及,当然就没有背过的那么快速干脆了,而对方在强调结果,也没给我思考分析的时间,我还在仔细回想这个里哪里存在惊群问题的时候,对方已经打断我说好了。所以这里就记录分析一下,到底什么是惊群效应,以及在并发编程中的应对方式。
简单粗暴理解,惊群效应就是,给一堆睡觉的鸟群 (羊群、牛群都行,随你高兴) 中,扔一颗石子,结果就是会惊醒这一群的鸟,这就是所谓的惊群效应。
对应到并发编程中,当多个线程阻塞到相同资源上 (比如锁) 时,当这个资源 ready 后,资源就绪的信号唤醒了所有阻塞到这个资源上的所有线程。
以锁为例,说明一下惊群的问题。比如某一个时刻 lock1 被其他线程占用,这个时候线程 A、线程 B、线程 C 来获取锁 lock1,则就都会被阻塞在 lock1 的阻塞队列中。当 lock1 被释放的时候,那么就会唤醒所有的阻塞在 lock1 上的线程 (这个不一定是唤醒所有线程,不同实现方式是有不一样的,java 的锁实现是唤醒所有线程的)。当线程 A、线程 B、线程 C 都被唤醒后,他们干的第一件事就是去争抢 lock1,最终只会有一个线程成功获取锁 (加入是线程 A),那么其他线程就又会重新被阻塞住,所以线程 B、线程 C 被唤醒啥也没干成,又被阻塞了。
要知道,线程的唤醒、挂起,都是需要通过系统调用的,操作系统也需要有一系列的动作老完成线程状态的转换,比如将线程从 lock1 阻塞队列中出队,然后放到 cpu 的就绪队列中,然后将线程状态变成 running,然后操作系统的 cpu 调度就才能给就绪队列中的线程分配 cpu。挂起线程,同样是需要逆向的这一些列动作的。然而对于线程 B、线程 C 唤醒 / 挂起,这些操作都是无用的,是对资源的浪费。当并发非常大,线程争抢一个锁的竞争非常大,那么就会有非常多的这种无用的唤醒 / 挂起,cpu 飙高了,但是业务响应反而变慢了。那么这个时候观察系统,会发现上下文切换变多了、中断也变多了。
总结起来就是:在并发编程中,当有多个线程 / 进程争抢同一资源,因资源不足而被阻塞的时,当阻塞事件解除后,如果唤醒了所有阻塞在该事件上的所有线程 / 进程,那就触发了惊群效应。
惊群效应的应对
在并发编程中,之所以出现了并发安全问题,是因为多个线程同时去修改相同的资源,所以随之而来的应对线程安全问题就是破坏这个条件,所以到处都会告诉你,应对并发安全问题:
- 不可变。这里破坏的就是 "修改" 这个条件。都不可变了,肯定是就没有问题了。但是这个应用场景其实是非常有限的,毕竟一个应用中,真的完全不变的数据并不是很多。但是在 java 变成中,要实现不可变,就得小心了,不是加个 final 修饰符就是不可变了,最稳妥的方式就是封装起来不听过任何修改方法,初始化后就不能该。
- 线程同步。这个破坏的就是 "多个" 条件。通过线程同步的方式,保证同一时刻只有一个线程去修改资源,其实就变成串行的了,自然也就不会有并发安全问题了。这也是最直观、最简单、实际生产中用的最多的方式了。所以几乎是只要提到线程安全,第一反应就是加锁,以至于如果谁深入思考后使用不可变 / 不共享来解决并发安全问题,要么就是被认为是不靠谱、要么就被认为是高阶操作。不过确实:加锁相对来说是更不容易出错一些,而不共享往往容易跌坑里。
- 不共享。这个破坏的就是 "相同资源" 的条件。只要不修改相同的资源,那么肯定就没有并发安全的问题了。但是只要说到不共享,第一反应肯定就是 ThreadLocal,但是好像也只能想到 ThreadLocal。而这里主要就想想要把不共享的思路打开。也从这个角度看下怎么去解决惊群效应。
对于不共享,ThreadLocal 其实就是给每个线程一个副本,自己玩自己的,那就不会共享了。把视角拉高一点,如果多个线程同时去修改相同的资源这句话中的资源,是可切分的、或者部分可切分呢?那是不是说当一个线程来修改的时候,就给这个线程分配一部分、让这个线程独占,依次类推 (当然,这里只是说的思路,实际实现的时候可能还是得配合锁)
JDK 中的例子就是 LongAddr,它的基本思想就是将一个数分成了量大部分:base 和多个 cell。当调用 add() 方法修改这个数的时候,先 CAS 尝试修改 base,如果不成功 (说明有竞争),那就找个 cell 给当前线程,让它修改这个 cell,这个时候线程是独占 cell 的,也就不存在竞争了;而当我们读取这个数的时候,就需要将 base 以及所有的 cell 进行合并,这里明眼一看就知道有数据一致性问题,所以 LongAdder 也是不使用一致性要求非常高的场景。
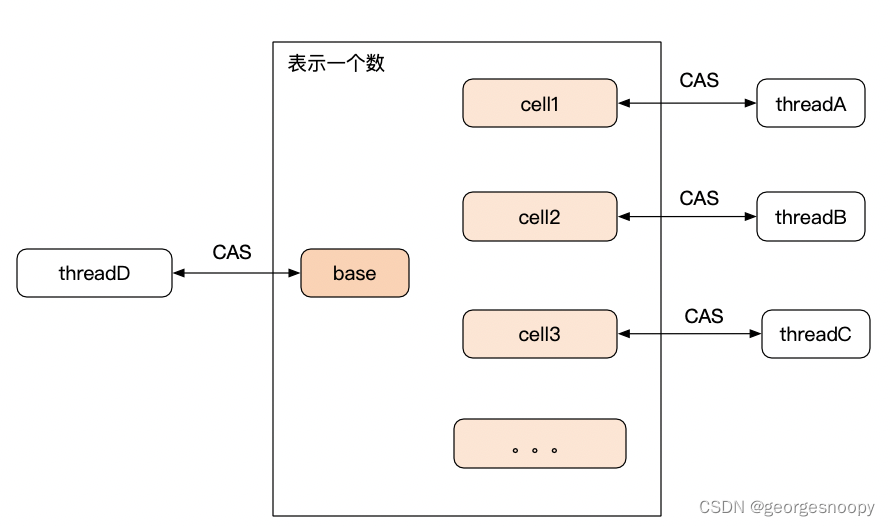
具体可参考:CAS vs 数据库乐观锁_georgesnoopy 的博客 - CSDN 博客。jdk 中另外的一个例子就是 ConcurrentHashMap,已经抛弃了 jdk7 中分段锁的实现,而是采用了 LongAdder 的这个思路来进一步优化了
基于这个思路,我们来看下惊群效应,之所以一颗石子会惊醒所有的鸟,不就是因为所有的鸟都睡在一起么,所以解决惊群的问题思路就两个:别让鸟都睡在一起;另一个就是叫醒的时候别都叫醒。
第一个思路:别让鸟都睡在一起,对应到锁的实现上,其实就是条件变量。一个锁可以关联多个条件变量,每个条件变量上一个阻塞队列,争抢同一个锁的线程不是都最在一个队列中,而是多个队列中,当一个条件发生时,只是唤醒对应的条件变量队列中的线程。
举个栗子:生产者 - 消费者模型中,会使用锁来防护那个装馒头的篮子,生产者和消费者都会去争抢这个篮子上的锁,但是抢到锁后,如果生产者发现篮子是满的,则继续挂起自己;消费者发现篮子是空的,则继续挂起自己。但是篮子从空变成不空了,会唤醒所有生产者、消费者线程,但这里起目的其实是想唤醒消费者消费的。有了条件变量就可以精准控制了:一个控制篮子为空、一个控制篮子满了,生产者发现篮子满了阻塞在队满条件变量上、消费者发现篮子为空阻塞在篮子空了的条件变量上。当篮子由空变成不空,只是唤醒篮子空了条件变量阻塞队列上的线程;当篮子由满变成不满,只是唤醒篮子满了条件变量阻塞队列上的线程,这样就会大大减少惊群效应。
所以我们可以看到,条件变量其实可以大大减少惊群效应,但是并不能消除。对于睡在同一卧的鸟还是会被同时唤醒。
另外一个思路就是:你特么的别扔石头一下子都叫醒,一个一个去喊不行么?
当然可以,但是到底喊谁呢?java 的实现就是随机,所以会看到条件变量唤醒线程都是有两个方法:notifyAll()-- 相当于扔石头,砸醒所有的鸟;还有一个 notify()-- 相当于随机去叫醒一只鸟。
这么看好像 notify() 更好呀,没有惊群效应了,只是搞醒了一只鸟,很棒。但是你会发现很多地方都不建议去使用 notify(),而是建议使用 notifyAll()。其原因就是防止线程饿死,一个线程可能一直都没有被随机到,那它就一直不会被唤醒。
站在系统调度的角度看,如果说被阻塞的这些线程,优先级不是一样的,有更高的优先级,那这种随机的方式,并不一定就会唤醒高优先级的那个线程,但是唤醒所有,操作系统调度就会考虑线程优先级的。
另外一个问题,为啥没有一个 notify(Thread t),让程序员来指定唤醒那个线程呢?扪心自问,你知道改怎么选么,到底该选哪个?如果再深入说下去,那是不是就得自己来实现一个调度框架了,调度框架来决定该唤醒哪个。
Socket 中的惊群
总结一下,出现惊群效应的场景:多个线程阻塞在相同资源上,当资源 ready 后,唤醒阻塞在该资源上的所有线程,而唤醒的所有线程中,其实只有一个能够成功获得这个资源。
基于此,我们来看 Socket 编程中哪些地方可能出现惊群,首先就是看哪些操作是阻塞的:
- 初始化 socket。初始化了 socket 的内存结构。不阻塞
- socket.bind。将 socket 和 ip + 端口绑定,只是修改内存数据,不阻塞。
- socket.liseten。将主动 socket 变成被动 socket,表示这个 socket 是用来监听客户端连接请求的,并开始监听客户端的链接请求。因为这个只是让服务端 Socket 处于侦听状态,listen() 系统调用本身是不阻塞的。
- socket.accept。去 listener 完全链接队列中获取连接,当完全链接队列中为空的时候阻塞当前线程。当完成三次握手链接建立后,操作系统内核会将连接放入到完全连接队列中,然后开始唤醒阻塞在完全连接队列上的线程。
- socket.connect。主动 socket 发起链接请求,背后就是三次握手。是阻塞的。
- socket.read/write。read 是从读缓冲区读取数据、write 是向写缓冲区写入数据。当读缓冲区空,则 read 阻塞;当写缓冲区满,write 阻塞。ps:当然也有不阻塞的重载。
所以总结起来看,整个 socket 编程中,会阻塞线程的就只有:
- 服务端 socket(被动 socket) 的 accept()。当多个线程都对同一个被动 Socket 调用了 accept() 后,如果完全链接队列是空的,那么这些线程都会阻塞到完全链接队列中;当有客户端与服务端完成三次握手,完成了连接建立,则内核会将这个连接放到完全队列中,并唤醒阻塞在这个完全连接队列中的线程。
- 客户端 socket(主动 socket) 的 connect()。这个确实会阻塞,但是不支持多线程调用,因为当三次握手完成,连接建立,这个连接就是对应到当前的这个 sokcet 中的。所以对一个已经完成三次握手连接的 socket 再次调用 connect(),会直接报错。因为不会出现多个线程阻塞在同一个队列中,那也就不会出现惊群问题了。
- 服务端 / 客户端 socket 完成通信的 read()/write()。对于 read(),实际是去读缓冲区获取数据,当读缓冲区是空的,当前线程就会阻塞在读缓冲区上。那么当多个线程使用相同的 socket 调用 read(),当读缓冲区是空的,则所有线程都会阻塞在这个 socket 的读缓冲区上。当对端发送来数据,网卡收到数据后,会将数据放到读缓冲区中。这个时候操作系统就会唤醒所有阻塞在读缓冲区上的所有进程。出现惊群效应。写也是一样的道理。
所以综上所述,在 Socket 编程中,有三个地方是阻塞的,但只有两个地方会出现多个线程阻塞在相同资源上的问题,所以也就只有两处可能存在惊群问题:serverSocket.accept() 和 socket.read()/socket.write()
linux 新版内核中,在阻塞队列中引入了 WQ_FLAG_EXCLUSIVE 标识,可以用它来解决惊群问题,基本思路是在进入到阻塞队列的时候给线程加上一个 WQ_FLAG_EXCLUSIVE 标识,当阻塞事件解除后,唤醒阻塞队列中的线程时,会依次遍历阻塞队列:遍历时如果阻塞队列中的线程没有 WQ_FLAG_EXCLUSIVE 标识,那就直接唤醒;当遇到第一个带有 WQ_FLAG_EXCLUSIVE 的线程时,同样去唤醒该线程,然后结束遍历。这样就保证了一次就绪事件发生,就只会唤醒一个 WQ_FLAG_EXCLUSIVE 标识的线程。
accept() 的惊群就是这么解决的,因为调用 accept() 而被阻塞的线程,进入阻塞队列的时候,就会被打上 WQ_FLAG_EXCLUSIVE 标识,这样当客户端连接请求到来的时候,就只会有一个因 accept 而阻塞的线程被唤醒,从而避免惊群问题。
从 linux 的 fork 子进程看,父进程中初始化了 listenFd(serverSocket 内封装那个 fd),然后 fork 出了子进程,子进程就将父进程中的 linstenFd 个 copy 过来了,所以多个进程就是公用了一个 listenFd,那这个时候都去调用 accept(listenFd),就存在多个进程都阻塞在 listenFd 上,从而引发惊群效应。
从 java 的角度看:使用线程池去调用同一个 serverSocket.accept(),这样就存在惊群问题,所以同样可以依靠内核的 WQ_FLAG_EXCLUSIVE 标识来解决。
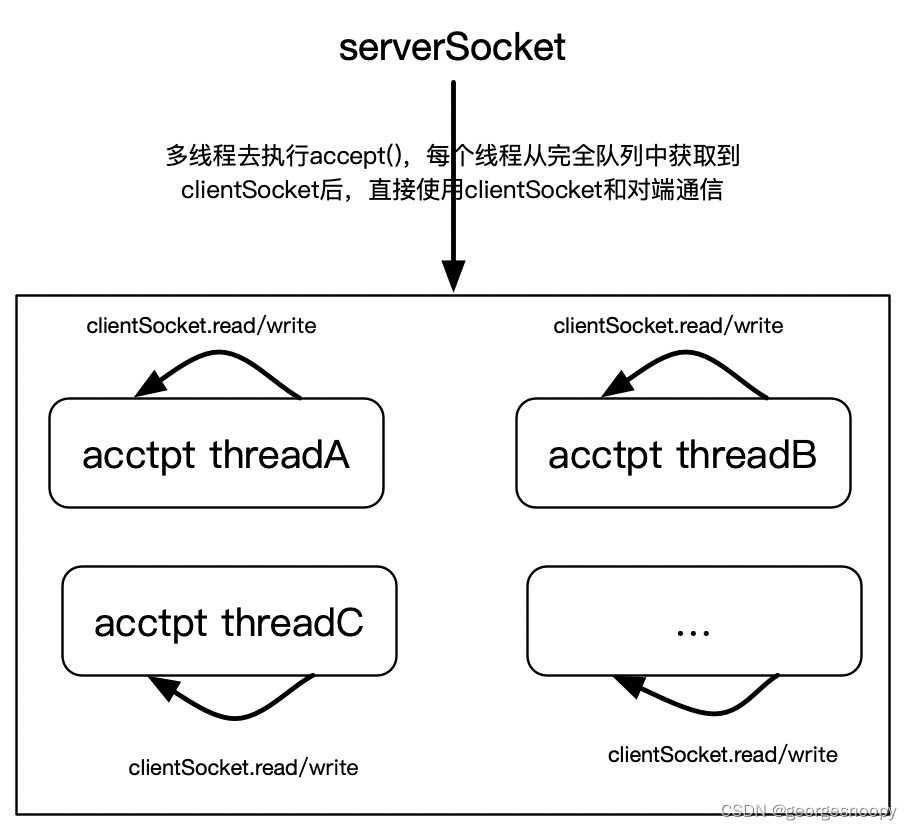
但是从另外一个角度,变换一个线程池设计,其实也就是可以避 accept() 的惊群的:那就是单线程执行 accept(),将 accept() 获得的 clientSocket 交给另外一个线程池去处理。
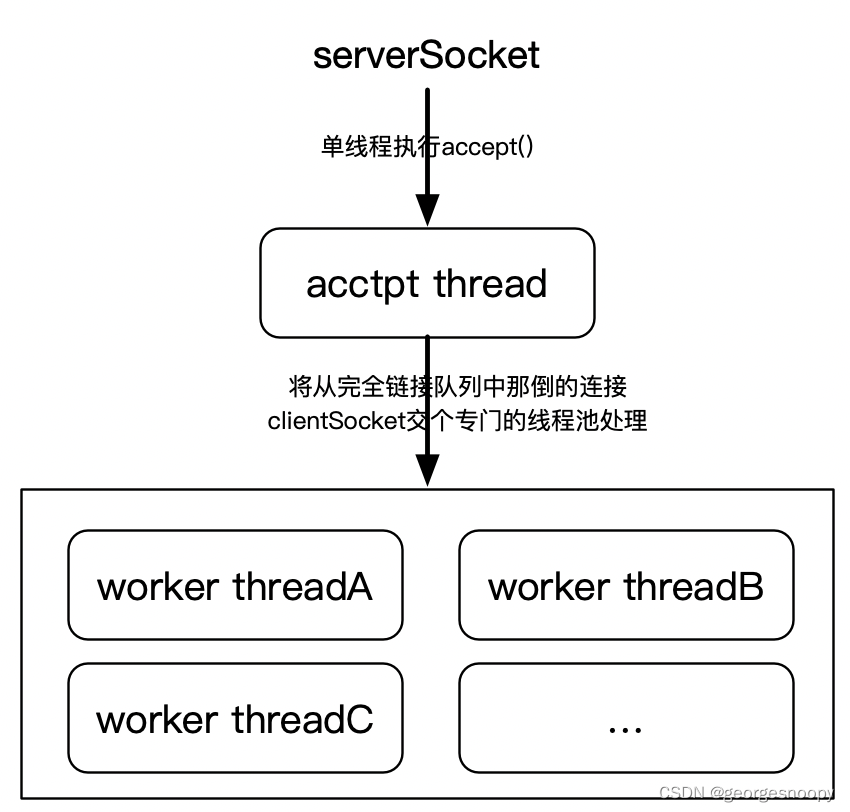
这种方式的问题就在于 accept() 是单线程的,如果网络并发非常大,以至于单程处理不过来,那么客户端的链接请求完成后,就会在完全队列中挤压,极端情况就是完全对了满了,已经链接上来的客户单通信延迟增大,而再有客户端连接请求,则会失败。
ps:accept() 操作很费时么?如果它仅仅是当三次握手完成后,从完全连接队列中获取链接,然后初始化 ClientSocket,那么这都是纯内存操作,岂不是应该很快才对 (Redis 的单线程很快不是就是因为单线程执行的操作都是纯内存操作么),linux 内核大神求解。
epoll 中的惊群
同样的,先来看 epoll 的哪些操作是阻塞的,再来分析是否有惊群问题
- epoll_create:初始化一个 epoll,即初始化那个红黑树、就绪队列结构。是不阻塞的。
- epoll_ctl:增删改查那个红黑树。比如将 ft 注册到 epoll 中、从 epoll 中删除等等。也是不阻塞的。
- epoll_wait。这个就是去轮询就绪队列的,看哪些 io 就绪了。这个操作是阻塞的
所以在 epoll 多路复用中,多线程调用 epoll_waite() 的时候,可能会导致惊群问题。具体参考:http://t.csdn.cn/i2mFP
jdk 线程池中的惊群
产生惊群的本质就多个线程阻塞在同一个资源上,当资源 readdy 的时候,会唤醒所有的线程,但唤醒的所有线程中,其实只有一个线程能够获得资源,其他线程又会被阻塞,所以其他线程就是无用的唤醒。
对于线程池就来看线程池中的线程是阻塞在哪里的?档案当然是线程池中的工作队列,而这个工作队列使用的是一个阻塞队列 BlockingQueue。所以问题就转换成线程池使用的阻塞队列,当队非空的时候,如何唤醒阻塞在这个队列上的线程了。
以比较常见的 ArrayBlockingQueu 和 LinkedBlockQueue 为例,会发现,当有元素入队的时候,唤醒线程它使用的是 signal() 方法,而不是 signalAll(),那么就只会随机唤醒一个阻塞在当前队列的中的线程 (notEmpty 是一个条件变量),所以,当使用这两个阻塞队列的时候,jdk 中的线程池是没有惊群问题的。
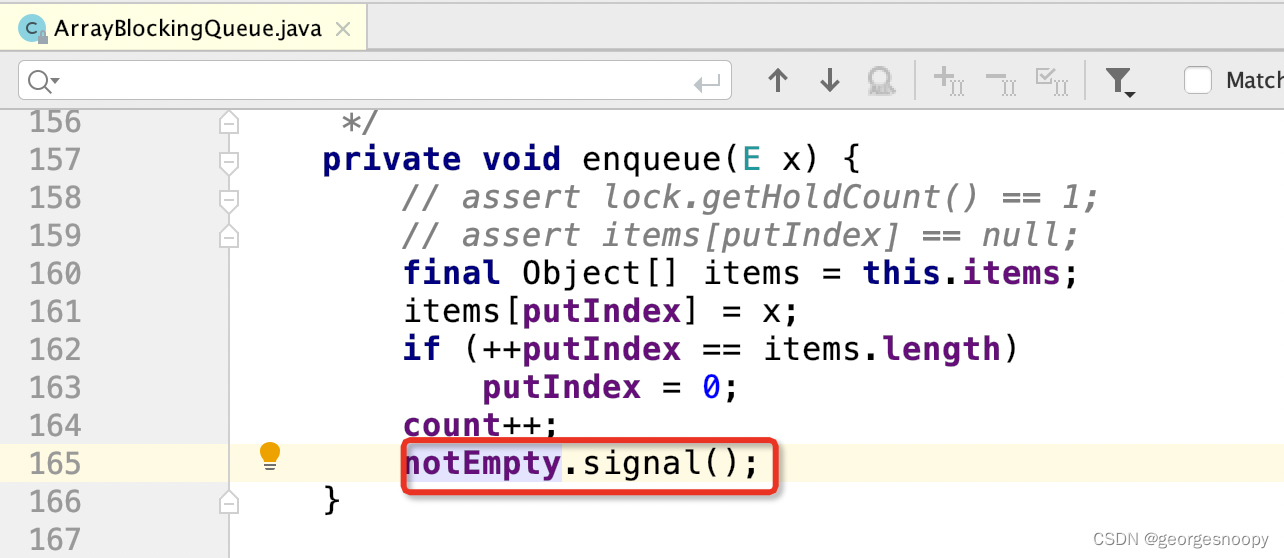
前面也说过,使用 signal() 方法唤醒的一个最大问题就是饥饿问题、特别是高优先级线程饥饿问题。但是对于线程池来说,其目的只是要求有线程来驱动执行提交过来的任务,但到底哪个线程来执行,是无所谓的,这里 care 的是任务,有优先级也是任务的优先级,而不是线程的优先级。在线程池中的线程是没有任何差别的。
ps:在学习操作系统的时候,肯定都看到过一个说法,线程就是任务、任务就是线程,这两者是可以等价的。这句话既对又不对。对是因为在操作系统中,线程和任务的生命期是一样的,线程执行完任务,线程也就消失了,所以从这个层面来说,这句话是对的。
但是在高级语言中的线程池,其实是将这两个概念分开了,对任务进行实现了更高层面的抽象:
- 线程:是对 cpu 资源的一个抽象,cpu 调度完全依赖线程这个概念,所以在高级语言中,就特指获取 cpu 的一个载体。
- 任务:是指一系列的指令。对应到高级编程语言来说,就是一段代码,比如 java 中可以任务 Runnable 接口就是任务,它可以提交给线程池让线程来执行 Runnable#run() 方法的代码。
所以从这个层面说,线程是去驱动任务来执行的。但一定要注意,如果对应到操作系统中的任务 (exec() 执行的指令序列),线程池中执行的任务还是 Runnable 么?答案是否定的,它实际上执行的是 blockingQueue.take().run()。所以 jdk 是利用了阻塞队列来实现了线程的复用。所以说 jdk 使用 Runnable 对任务实现了进一步高于线程概念的抽象。