缓存 LRU LFU W-TinyLFU算法
https://juejin.cn/post/6844904131883171847
LFU和LRU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数的。
Caffine 采用W-TinyLFU
- 过期策略
LFU 算法需要额外记录访问次数,最简单的做法就是用一个大的 hashmap 存储每个数据的访问次数,但是当数据量非常大的时候,hashmap 占用的空间也非常大。
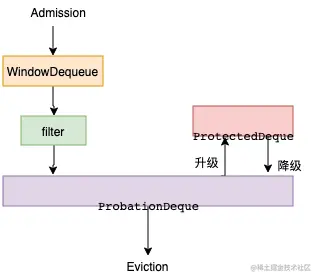
在W-TinyLFU中,数据首先会进入到 Window LRU, 从 Window LRU 中淘汰后,会进入到过滤器中过滤,当新来的数据比要驱逐的数据高频时,这个数据才会被缓存接纳,这么做的目的主要是为了使新数据积累一定的访问频率,以便于通过过滤器,进入到后面的缓存段中。 - 分段LRU
对于长期保留的数据,W-TinyLFU 使用了分段 LRU 策略。起初,一个数据项存储被存储在试用段(ProbationDeque)中,在后续被访问到时,它会被提升到保护段(ProtectedDeque)中(保护段占总容量的 80%)。保护段满后,有的数据会被淘汰回试用段,这也可能级联的触发试用段的淘汰。这套机制确保了访问间隔小的热数据被保存下来,而被重复访问少的冷数据则被回收。 - 读写优化 , 淘汰时 异步操作
- readBuffer RingBuffer