#大顶堆 小顶堆
大顶堆:每个结点的值都大于或等于其左右孩子结点的值。 小顶堆:每个结点的值都小于或等于其左右孩子结点的值。 堆就是利用完全二叉树的结构来维护的一维数组。 大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2] 小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2] 其中arr[2i+1]是左节点 arr[2i+2]是右节点
最大的 K 个:小顶堆 最小的 K 个:大顶堆
深度优先搜索 : 其实就是沿着一个方向一直向下遍历. 广度优先搜索: 一个层级level先遍历 二叉搜索树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉搜索树。
满二叉树: 如果二叉树中除了叶子结点,每个结点的度都为 2,则此二叉树称为满二叉树。 完全二叉树: 如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树
堆排序, 这样排序不需要占用额外的空间,只需要交换元素的需要一个临时变量,所以堆排序的空间复杂度为O(1) 。
(1)堆是一颗完全二叉树; (2)小(大)顶堆中的每一个节点都不小于(不大于)它的父节点; (3)堆的插入、删除元素的时间复杂度都是O(log n); (4)建堆的时间复杂度是O(n); (5)堆排序的时间复杂度是O(nlog n); (6)堆排序的空间复杂度是O(1) ; 堆排序很少用 一句话就是:因为堆排序下,数据读取的开销变大。在计算机进行运算的时候,数据不一定会从内存读取出来,而是从一种叫cache的存储单位读取。原因是cache相比内存,读取速度非常快,所以cache会把一部分我们经常读取的数据暂时储存起来,以便下一次读取的时候,可以不必跑到内存去读,而是直接在cache里面找。
#堆和普通树的区别
- 内存占用: 普通树占用的内存空间比它们存储的数据要多。你必须为节点对象以及左/右子节点指针分配额外的内存。堆仅仅使用数组,且不使用指针
- 平衡: 二叉搜索树必须是“平衡”的情况下,其大部分操作的复杂度才能达到O(nlog2n)。你可以按任意顺序位置插入/删除数据,或者使用 AVL 树或者红黑树,但是在堆中实际上不需要整棵树都是有序的。我们只需要满足对属性即可,所以在堆中平衡不是问题。因为堆中数据的组织方式可以保证O(nlog2n) 的性能
- 搜索: 在二叉树中搜索会很快,但是在堆中搜索会很慢。在堆中搜索不是第一优先级,因为使用堆的目的是将最大(或者最小)的节点放在最前面,从而快速的进行相关插入、删除操作
#大顶堆的构建过程
大顶堆的构建过程就是从最后一个非叶子结点开始从下往上调整。 最后一个非叶子节点怎么找?这里我们用数组表示待排序序列,则最后一个非叶子结点的位置是:数组长度/2-1。假如数组长度为9,则最后一个非叶子结点位置是 9/2-1=3。 比较当前结点的值和左子树的值,如果当前节点小于左子树的值,就交换当前节点和左子树; 交换完后要检查左子树是否满足大顶堆的性质,不满足则重新调整子树结构; 再比较当前结点的值和右子树的值,如果当前节点小于右子树的值,就交换当前节点和右子树; 交换完后要检查右子树是否满足大顶堆的性质,不满足则重新调整子树结构; 无需交换调整的时候,则大顶堆构建完成。
画个图理解下,以 [3, 7, 16, 10, 21, 23] 为例:
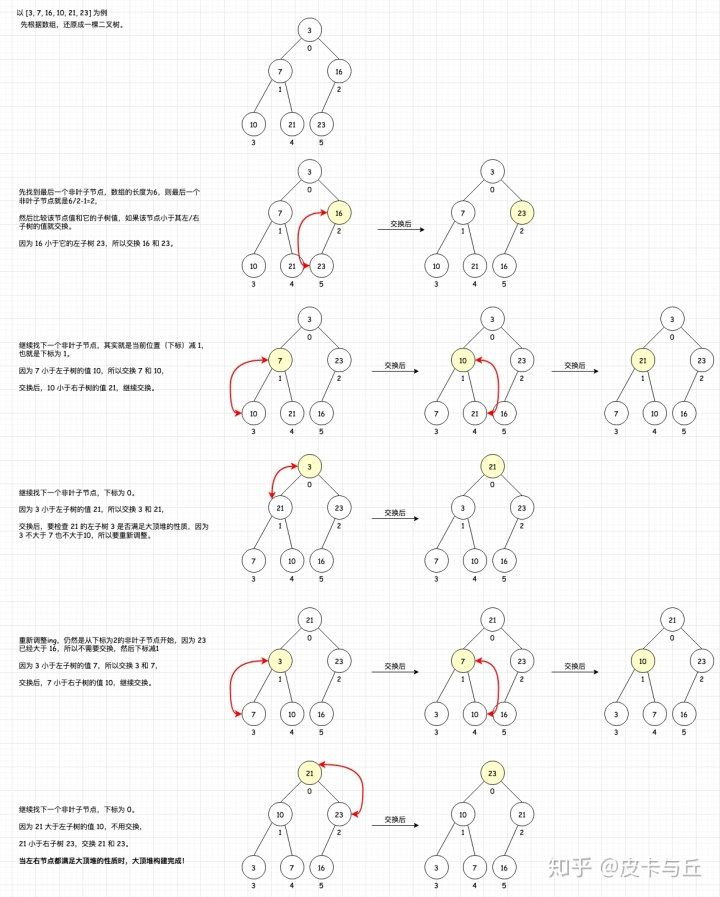
#二叉树的很多计算,可以用 递归 或者迭代解决
https://www.jianshu.com/p/15a29c0ace73 https://zhuanlan.zhihu.com/p/335322846