#AI - 自然语言处理 - 关键词提取
原文地址 blog.csdn.net
学习目标
• 了解自然语言处理基本知识
• 掌握循环神经网络算法
• 掌握自然语言处理关键技术
• 了解自然语言处理的应用
关键词提取
定义
• 关键词是代表文章重要内容的一组词,现实中大量文本不包含关键词,因此自动提取关键词技术能使人们便捷地浏览和获取信息,对文本聚类、分类、自动摘要等起重要的作用。
• 关键词提取算法一般也可以分为有监督和无监督两类。
• 有监督:主要是通过分类的方式进行,通过构建一个较为丰富和完善的词表,然后通过判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到提取关键词的效果。
• 无监督:不需要人工生成、维护的词表,也不需要人工标准语料辅助进行训练。例如,TF-IDF 算法、TextRank 算法、主题模型算法(LSA、LSI、LDA)。
TF - IDF 算法
• 词频 - 逆文档频率算法(Term Frequency-Inverse Document Frequency,TF-IDF ): 是一种基于统计的计算方法,常用于评估在一个文档集中一个词对某份文档的重要程度。
• 例如:
世界献血日,学校团体、献血服务志愿者等可到血液中心参观检验加工过程,我们会对检验结果进行公示,同时血液的价格也将进行公示。
• 其中,“献血”、“血液”、“进行”、“公示” 等词出现的频次均为 2,如果从 TF 算法的角度,他们对于这篇文档的重要性是一样的。但是实际上明显 “血液”、“献血” 对这篇文档来说更关键。
• TF 算法:是统计一个词在一篇文档中出现的频次。其基本思想是,一个词在文档中出现的次数越多,则其对文档的表达能力也就越强。

• IDF 算法:是统计一个词在文档集中的多少个文档中出现。其基本思想是,如果一个词在越少的文档中出现,则其对文档的区分能力也就越强。
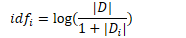
• 其中,|D | 为文档集中总文档数,|D_i | 为文档集中出现词 i 的文档数量。
• TF-IDF 算法:tf×idf(i,j)=〖tf〗_ij×〖idf〗_i=n_ij/(∑_k▒n_kj )×log((|D|)/(1+|D_i |))
TextRank 算法
• TextRank 算法的基本思想来源于 Google 的 PageRank 算法。PageRank 算法是 Google 创始人拉里. 佩奇和谢尔盖. 布林于 1997 年构建早期的的搜索系统原型时提出的链接分析算法,该算法是用来评价搜索系统覆盖网页重要性的一种方法。其基本思想有两条:
• 链接数量。一个网页被越多的其他网页链接,说明这个网页越重要。
• 链接质量。一个网页被一个越高权值的网页链接,也能表明这个网页越重要。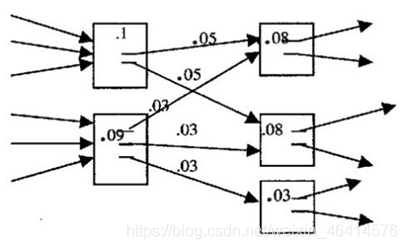
• TextRank 与其他算法的区别:可以脱离语料库的背景,仅对单篇文档进行分析就可以提取该文档的关键词。
• TF-IDF 中需要统计每个词在语料库中的多少个文档有出现过,也就是逆文档频率。
• 主题模型则要通过对大规模文档的学习,来发现文档的隐含主题。
• TextRank 算法最早用于文档的自动摘要,基于句子维度的分析,利用 TextRank 对每个句子进行打分,挑选出分数最高的 n 个句子作为文档的关键句,以达到自动摘要的效果。
• In(V_i) 为 V_i 的入链集合,Out(V_j ) 为 V_j 的出链集合,|Out(V_j )| 是出链的数量,因此 V_i 自身的得分为:
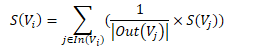
• 为了避免孤立网页得分为 0,因此加入一个阻尼系数 d,如下:
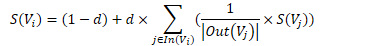
• PageRank 是有向无权图,TextRank 进行关键词提取时则是有权图,考虑在同一个窗口内词的共现。因此,TextRank 的完整表达式为:
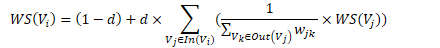
• 当 TextRank 算法应用到关键词抽取任务时,与在自动摘要任务中应用相比,主要有两点不同:
• 词与词之间的关联没有权重。
• 每个词不是与文档中所有的词都有链接。
• 由于第一点不同,此时 TextRank 中的分数就退化为与 PageRank 一致;对于第二点不同,链接关系可以通过窗口来界定。
LSA/LSI/LDA 算法
• 主题模型认为在词与文档之间没有直接的联系,它们应当还有一个维度将它们串联起来,这个维度称为主题。每个文档都应该对应着一个或者多个主题,而每个主题都会有对应的词分布,通过主题就可以得到每个文档的词分布。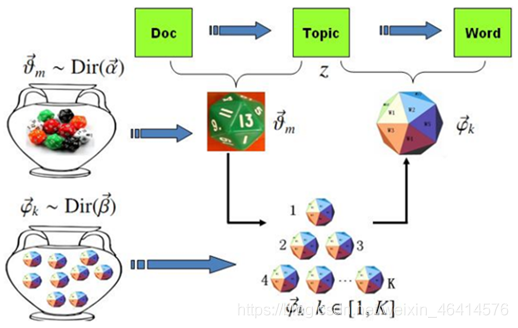
• 一般来说,TF-IDF 算法和 TextRank 算法就能满足大部分关键词提取的任务。但是在某些场景基于文档本身的关键词提取还不是非常足够,有些关键词并不一定会显示的出现在文档中,如一篇讲动物生存环境的科普文,通篇介绍了狮子老虎鳄鱼等各种动物的情况,但是文中并没有显示的出现动物二字,在这种情况下,前面的两种算法就不适用了,这时候就需要用到主题模型。
• 前面两种模型是直接根据词与文档的关系,对关键词进行抽取。这两种方法仅用到了文本中的统计信息,对文本中丰富的信息无法充分地进行利用,尤其是其中的语义信息,对文本关键词的抽取显然是一种非常有用的信息。
• LSA\LSI 算法
• LSA(Latent Semantic Analysis,潜在语义分析)和 LSI(Latent Semantic Index,潜在语义索引)都是对文档的潜在语义进行分析,但是潜在语义索引在分析后,还会利用分析的结果建立相关的索引,二者通常被认为是同一种算法。其步骤为:
• 使用 BOW 模型将每个文档表示为向量。
• 将所有文档词向量拼接起来构成词 - 文档矩阵(m×n)
• 对词 - 文档矩阵进行 SVD 操作([m×r].[r×r].[r×n])。
• 根据 SVD 的结果,每个词和文档都可以表示为 r 个主题构成的空间中的一个点,通过计算每个词和文档的相似度,可以得到每个文档中对每个词的相似度结果,取相似度最高的一个词即为文档的关键词。
• 相较于传统 SVM 模型(Space Vector Model,空间向量模型)对语义信息利用的缺乏,LSA 通过 SVD 将词、文档映射到一个低维的语义空间,挖掘出词、文档的浅层语义信息,从而对此、文档进行更本质地表达。
• 优点:可以映射到低维空间,并在有限利用文本语义信息的同时,大大降低计算的代价,提高分析质量。
• 缺点:(1)SVD 的计算复杂度非常高,特征空间维度较大的,计算效率十分低下。(2)LSA 得到的分布信息是基于已有数据集的,当一个新的文档进入到已有的特征空间时,需要对整个空间重新训练,以得到加入文档后对应的分布信息。(3)对词的频率分布不敏感、物理解释性薄弱。
• LDA 算法
• LDA 算法假设文档中主题的先验分布和主题中词的先验分布都服从狄利克雷分布。然后通过对已有数据集的统计,就可以得到每篇文档中主题的多项式分布和每个主题对应词的多项式分布。训练过程一般如下:
• 随机初始化,对语料中每篇文档中的每个词 w,随机地赋予一个 topic 编号 z。
• 重新扫描语料库,对每个词 w 按照吉布斯采样公式重新采样它的 topic,在语料中进行更新。
• 重复以上语料库的重新采样过程直到吉布斯采样收敛。
• 统计语料库 topic-word 共现频率矩阵,该矩阵就是 LDA 的模型。
• 经过以上的步骤,就得到一个训练好的 LDA 模型,接下来就可以按照一定的方式针对新文档的 topic 进行预估,具体步骤如下:
• 随机初始化,对当前文档中的每个词 w,随机地赋予一个 topic 编号 z。
• 重新扫描当前文档,按照吉布斯采样公式,重新采样它的 topic。
• 重复以上过程直到吉布斯采样收敛。
• 统计文档中的 topic 分布即为预估结果。