Q
博客/wiki/知识库/文章收藏
时间轴
ALL
技术
ERP
搜索
技术
/
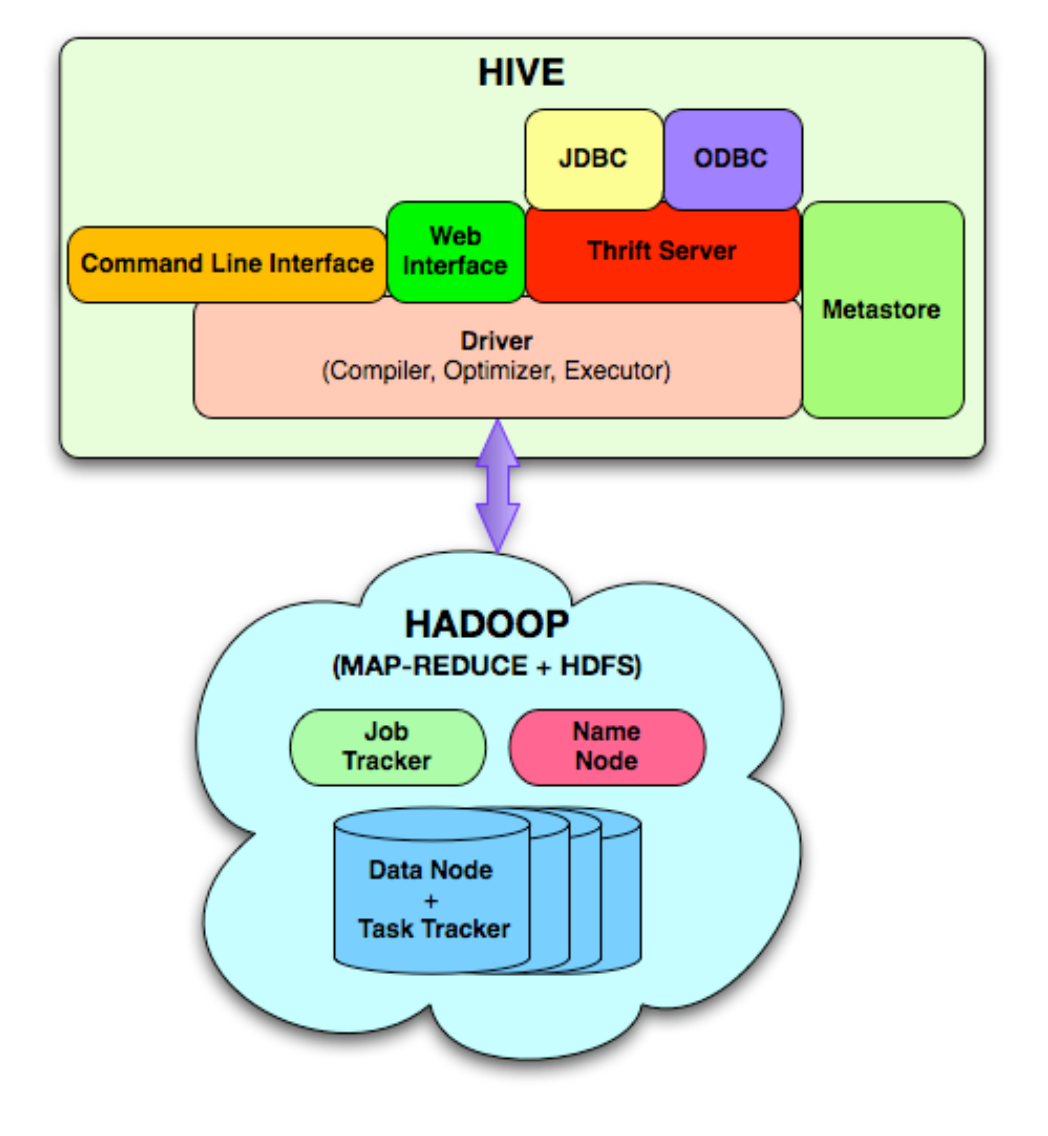
大数据-Hive Spark - 批处理
#
大数据-Hive Spark - 批处理
MapReduce中间过程 每次读写硬盘,Spark 根据窄依赖 宽依赖 判断,将中间结果存储到内存中。加速